This project is a vocabulary assessment game that generates English-sounding words using Z3 and linguistics principles.
Frontend and Backend Developer
Nadia Bitar, Sarah Ridley, Kathy Sun, Adelina Zheng
April - May 2026
React, Python, Z3
I worked on this project on a team of 4 for my final project as a student in LING0130: The Linguistics of Wordplay. While this class primarily focused on the linguistics behind word games like Scrabble, it also explored the phonotactic rules that govern how sounds can be combined to form words in English.
Our idea was to use these phonotactic rules to generate made-up words that sound like they could be English words, and create a game where players have to decide whether they recognize this word or not. This would be the backbone for a game that assesses the scope of a player's vocabulary.
As the backend developer on the team, I used Z3, a powerful constraint solver, to generate these words based on the phonotactic rules we researched and then encoded. We then collaborated to build a frontend for our game using React, and a backend in Python to handle the word generation and game logic.
The core problem is assessing a player's vocubulary in a fun way that doesn't require the player to tediously type out the definition of words (which could also be hard to assess). So, instead, we just ask players whether they recognize a word or not! But, we need to also ensure that players don't cheat and claim to recognize every word.
Our solution is to include our made-up words as a “spot-check” to disincentivize players from just saying they know every single word. This creates a quick, easy, and accessible vocabulary assessment game to encourage learning and vocabulary growth!
Our process involved several phases to design and implement the application:
Identify necessary constraints and generate made-up words and evaluate their quality. Refine the code as needed until generated words are “English-like” enough.
Refine the game features and design the user interface. Create a Figma mockup of the game and share it with the team for feedback.
Connect our Figma design to a frontend. Integrate our generated words with real English words. Set up scoring system and finalize game design.
The central challenge of this project was that as we began encoding our phonotactic constraints, specifically those from linguistic Heidi Harley, we found that they were not sufficient to generate words that sounded English-like enough. So, we had to iteratively add more constraints, including sonority sequencing constraints and others, to ensure that our generated words sounded like they could be English words. This was a fun challenge to work through, and we learned a lot about the interactions between different phonotactic rules and how they shape the structure of English words.
To encode Harley's phonotactic constraints, we referenced her framework for understanding the permissible sequences of sounds in English words. Harley defines 14 constraints, enumerated below.
Several of these constraints reference phonological classes. For example, Phonotactic Rule #7 requires that "The second consonant in a two-consonant onset must not be a voiced obstruent". So, to encode these rules, we had to define the following phonological classes: vowels, glides, liquids, nasals, fricatives, affricates, stops, voiced, voiced obstruents, alveolars, and velars .
This is non-trivial! One grapheme can represent multiple phonemes, for example, the grapheme "c" can represent both /k/ (the word "cat") and /s/ (the word "cent"). Also, some of these categories overlap, so our graphemes can also appear in multiple phonological classes.
We handled each grapheme on a case-by-case basis when grouping them into phonological classes, while also referencing the Standard American English Phoneme/Grapheme Chart for guidance on classifying graphemes. Some classifications were easy, for example, we know which graphemes are always vowels. Some graphemes are sometimes vowels, but we excluded these from our vowels class, because we do not have to be exhaustive! In other words, we don't have to generate every possible English-sounding word, just some words that sound like English. So, we chose to be conservative with our encoding decisions!
Many other choices were hard, and our classification is imperfect! For example, we classified the grapheme 'c' as a fricative, but 'c' can be a stop or a fricative. We found that we preferred 'ck' to appear in our words as a stop, as 'c' alone is more rare in English as a stop, so we classified 'ck' as a stop only and 'c' as a fricative only.
Below is our final classification of graphemes into phonological classes:
With our phonological classes already defined, we used them again to encode sonority sequencing. The principles of sonority sequencing state that syllables should have rising sonority in the onset, and falling sonority in the coda.
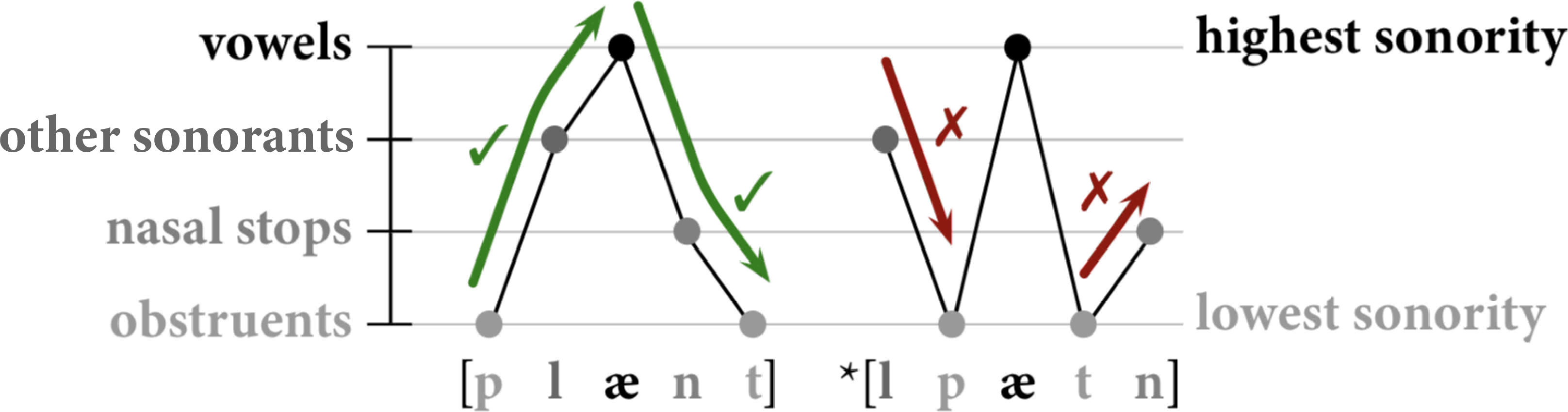
We used our phonological classes to encode these sonority sequencing constraints, which helps ensure that the generated words follow natural English syllable structure. This is critical to making sure our generated words sound like they could be English words, which is important for the quality of our game and the user experience.
Finally, we added a few more of our own constraints to make this constraint-solving feasible. First, we constrained that our words must have 2 or 3 syllables. This means we miss out on generating so many potential words, but we wanted to stick to shorter but interesting words for our assessment.
We also constrained the maximum number of graphemes in our onsets to 3, to allow for onsets like “str” in “string”. Similarly, we constrained the maximum number of graphemes in our codas to 4, because English only allows up to 4 phonemes per complex coda. However, we did not encode “ed” as a possible grapheme, so we would never generate words like “glimpsed”. And again, we chose to be conservative with our constraints, so we cannot generate every possible English-sounding word.
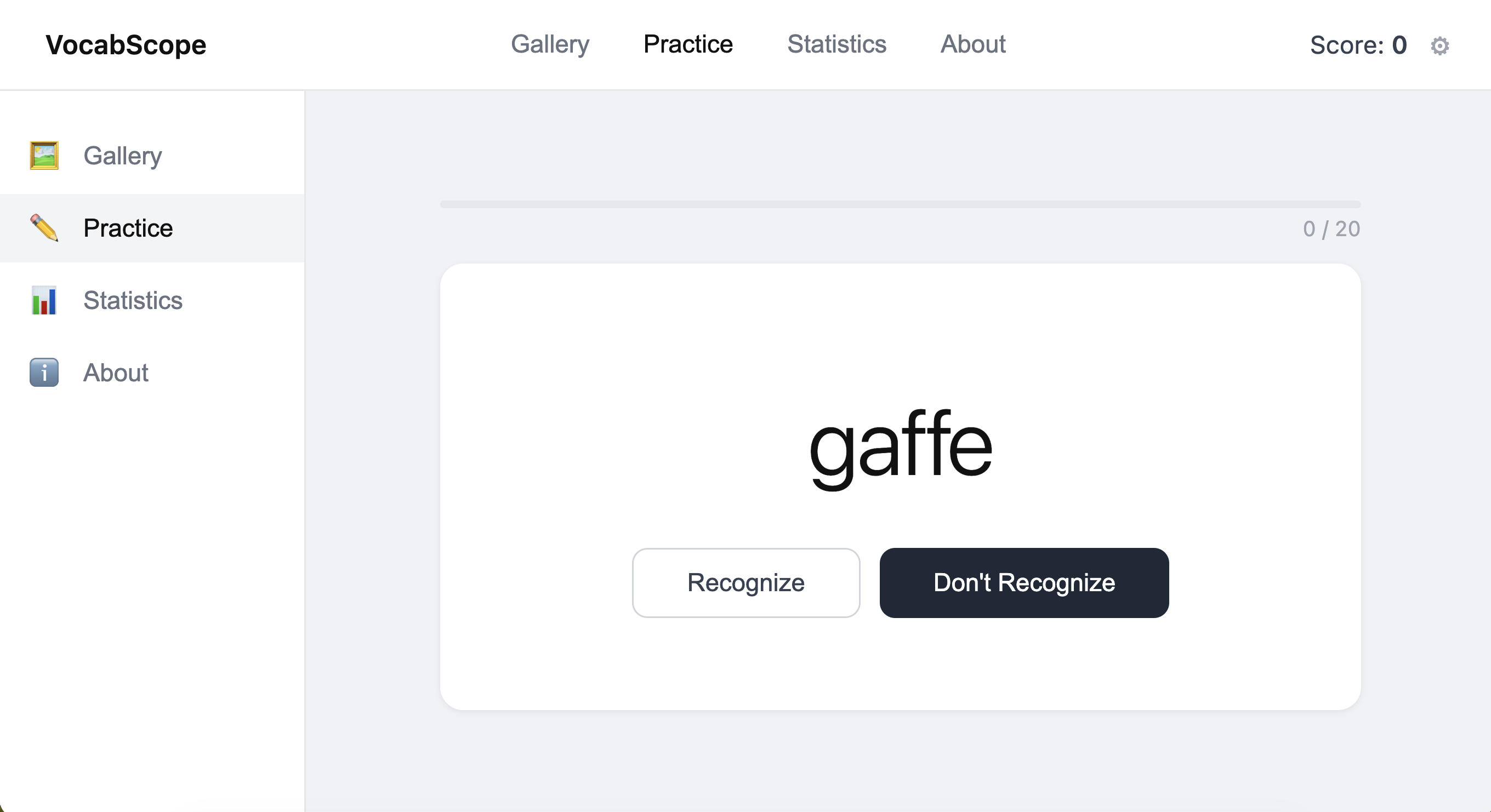
Here is our final game design, which we iteratively developed based on our testing against our preferences. With more time, we would have loved to conduct more user testing and feedback sessions to further refine our design.
You can play our game here, or by clicking below!
I learned a lot about linguistics from this project, including that Harley's phonotactic rules alone were not enough to make our words sound like English, which is why we added more general sonority sequencing constraints (and others). I also learned more about the interesting interactions between Harley's phonotactic rules! For example, we found that rules 6 + 7 + 8 nearly fully specify two-consonant onsets. So, we rarely generated three-consonant onsets, despite allowing them.
To extend this project, it could be valuabke like to add definitions to the real words to help players grow their vocabulary. To avoid challenges going back and forth between phonology and orthography, it would be interesting to explore an audio generation feature. The prompt could be an audio recording rather than written text, which could also be more accessible and account for words that someone has heard spoken but not written. We could also add further gamification, including leaderboards and rankings to encourage friendly competition.
More on the engineering side, I enjoyed applying Z3 to a linguistics problem and learning how to use it to generate strings based on constraints. This project took many rounds of iteration and adding new constraints to reach the goal of English-sounding words, which was great practice with refining and tweaking a Z3 model iteratively. I also used Z3 in my honors thesis project, LLMMarshal, so it was interesting to see how I could apply it in a different context and for a different purpose. I'm exciting to continue using Z3 and other constraint solving tools in the future.